
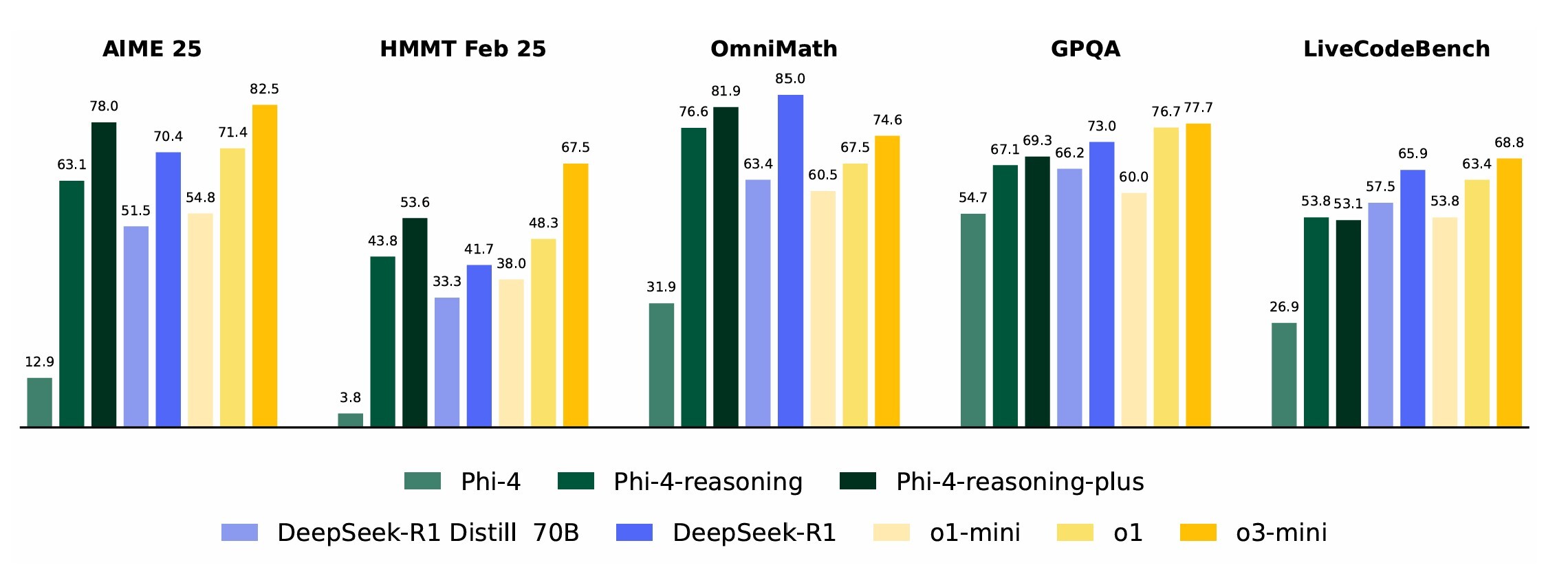
In the present day, Microsoft introduced Phi-4-reasoning, a 14B-parameter small reasoning mannequin that’s mentioned to ship sturdy efficiency on advanced reasoning duties. Microsoft educated this new mannequin by way of supervised fine-tuning of Phi-4 on a curated set of “teachable” prompts generated utilizing o3-mini. Microsoft additionally launched Phi-4-reasoning-plus, a 14B-parameter variant of Phi-4-reasoning that delivers even higher efficiency by producing longer reasoning traces.
In line with Microsoft’s whitepaper, these new Phi-4-reasoning fashions outperform a number of bigger open-weight fashions, reminiscent of DeepSeek-R1-Distill-Llama-70B, and even match the efficiency ranges of the complete DeepSeek-R1 mannequin on sure benchmarks. They’re additionally mentioned to outperform Anthropic’s Claude 3.7 Sonnet and Google’s Gemini 2 Flash Considering fashions on all duties besides GPQA and Calendar Planning.
The spectacular claimed efficiency of Phi-4-reasoning suggets that cautious knowledge curation for supervised fine-tuning (SFT) is efficient for reasoning language fashions, and efficiency could also be additional improved utilizing reinforcement studying (RL).
Phi-4-reasoning has a number of limitations as effectively. First, the Phi-4 mannequin primarily works with English textual content. Second, it’s primarily educated on Python utilizing frequent coding packages. Third, it has a context size of simply 32k tokens. Extra limitations might be discovered within the whitepaper.
Introducing Phi-4-reasoning, including reasoning fashions to the Phi household of SLMs.
— Ahmed Awadallah (@AhmedHAwadallah) Could 1, 2025
The mannequin is educated with each supervised finetuning (utilizing a fastidiously curated dataset of reasoning demonstration) and Reinforcement Studying.
📌Aggressive outcomes on reasoning benchmarks with… pic.twitter.com/p2FkjD4qfu
Microsoft acknowledged that these new Phi-4-reasoning fashions are designed to speed up analysis on language fashions. They’re anticipated to be helpful for creating AI purposes in memory- or compute-constrained environments, latency-bound situations, and reasoning-intensive duties.
builders can take a look at these new fashions at Hugging Face and Azure AI Foundry.
No Comment! Be the first one.